Project Description
The management of large computing systems and datacenters is becoming increasingly complex. On the one hand, these infrastructures are becoming more diverse and consist of different kinds of computers and hardware platforms in order to handle applications with different needs. For example, graphics processing units (GPUs) are widely used for artificial intelligence (AI) and machine learning applications, and Non-Volatile Memory (NVM) is used for certain data-intensive applications. On the other hand, infrastructures and applications are also becoming more sensitive to location in order to handle the growing demand for services everywhere.
Dealing successfully with these complex scenarios nowadays requires a holistic approach considering not only the computational component of applications, but also how data move from the beginning to the end of the pipeline. Therefore, there’s a need to take into account:
1) The orchestration of datacenter resources to decide where and how each application is executed.
2) Advanced modeling techniques to understand how applications behave.
3) Location awareness to provide better services to end users.
The majority of large computing systems today is either based on the Cloud, or operates like the Cloud. In these Cloud-like environments, computational resources are shared between different applications, and it is particularly important to design strategies to make sure that each application is using the right amount of resources at all times, without having an impact on other applications. For example, if an application is using too many resources, it is not good for the overall system because it may be preventing other applications from running faster.
The current techniques used to handle the diverse set of hardware options and different kinds of applications in datacenters are based on AI-methods and machine learning in the form of heuristics, predictors, or decision making assistants. In addition, thanks to advances in Deep Learning, complex and multidimensional data can be exploited in order to discover usage patterns on high performance applications, allowing to tune the system according to inferred behaviors and models.
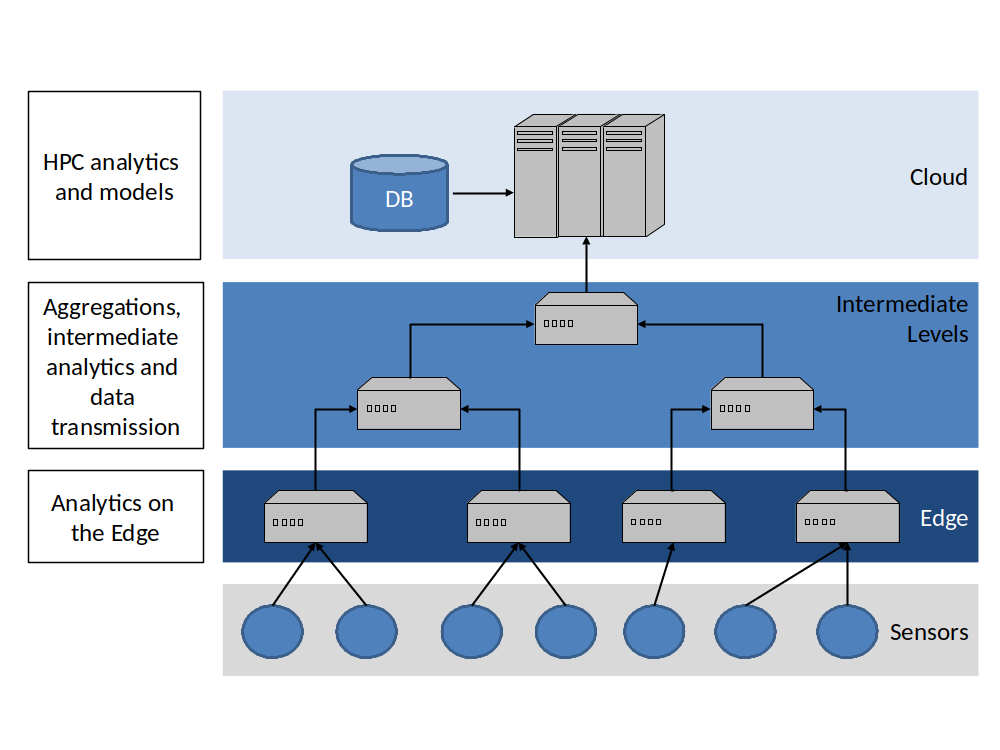
Finally, applications are also increasingly dependent on performing some sort of processing at different locations closer to the users, also called the Edge, to provide faster and better services. In this context, the incipient federated learning techniques provide a new paradigm towards distributing analytics and modeling processes in scenarios that need to be more aware of the location, such as the Edge and near-data sources, allowing scalability of data processing while also helping preserve privacy.
CALLISTO provides an excellent scenario to explore these techniques and bring machine learning and deep learning models to extreme conditions given the proposed use cases that involve large amounts of geospatial data.
Project Details
- DateJuly 29, 2021
- WriterBarcelona Supercomputing Center (BSC)
- 3
