Project Description
As we deal with big amounts of data in CALLISTO, it is important that all the processes are as fast and efficient as possible while retaining readability and easiness of reuse in code. In order to make execution faster, we might require optimization at the level of data centres or multiple machines, for example splitting processes and performing parallel computations. We also might require optimizations at code level using knowledge of the underlying computing architecture, which could include High Performance Computing elements like GPUs.
The focus is mainly set in finding the bottlenecks of the code. These bottlenecks are the parts of the code that are more use and/or take more time compared to the rest. Gene Amdahl defined his Amdahl’s law [1] for system speed-ups which can be summarised and adapted as “the performance improvement obtained by optimizing a part of the code is limited to the fraction of time that the improved part is used”. When thinking about it, it is pretty intuitive that the time that you will be able to reduce is the time that is being currently used to execute the particular piece of code that is being optimized. This means that we need to focus on the “heavy” parts of the code to get better results instead of optimizing everything.
Speeding up performing code optimizations
A big part of the data-intensive processes in the project are written in Python. This programming language provides a very flexible and easy to use syntax that enables researchers to test their ideas with fast prototypes and then to build stable production components. Python specially excels in readability because of its syntax and in its code reusability because of its object oriented nature. It is also possible to test the code doing step-by-step execution due to the fact that this code is interpreted by a python interpreter, which translates in an on-line fashion from python to byte-code that the machine can understand. However, due to its interpreted nature, it has an overhead over traditional compiled languages, like C.
Following Amdahl’s law, we focus on optimising the pieces of code that take more time to execute in the global scope of the execution. Those pieces can be found performing profiling techniques or the experts in charge of the code can already identify them. In order to overcome Python’s overhead in execution we focus on two particular packages/frameworks: Numba and Cython.
Numba is a JIT (Just In Time) compiler which receives the interpretable Python code and compiles the parts that are annotated to be processed on the execution. This process produces a machine level code which is faster than the original interpreted code. It offers general optimizations for a subset of Python and NumPy code with just simple code annotations that can be easily performed.
On the other hand, Cython is a static compiler. This means that the code is compiled before executing, therefore there is no translation overhead. Cython produces C-level like code, which means that when it is correctly used it produces very efficient code for execution. However, this approach requires to rewrite the code in Cython, which is a mix between Python and C, making it Cython dependent.
We have tested both approaches, using Numba and reimplementing critical code in two of the workloads present in the CALLISTO platform.
The first one is a workload that creates hashes for images enabling fast multi-modal indexing [4] and has several parts. In particular, there was a bottleneck in optimizing a mathematical function (training) which could be optimized. In the following figure we see that just annotating it with Numba already provides around a 30x of speed-up on average. However, if we reimplement that function in Cython we can achieve up to an 80x of speed-up on average.
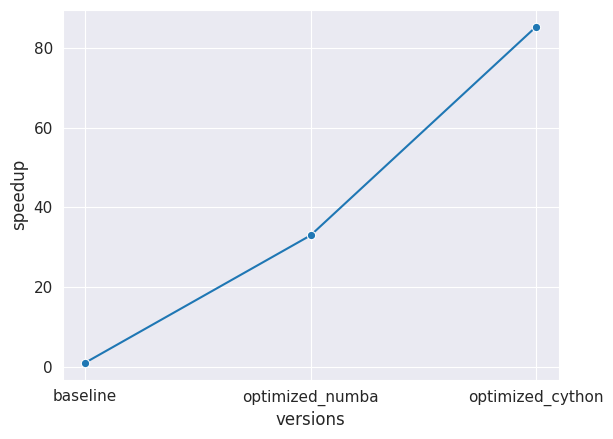
Numba/Cython Multi-modal Hash training optimization
The second workload is a path planer for Unmanned Aerial Vehicles (UAV)[5]. This workload was already optimized using Numba. Reimplementing the critical functions with Cython led to a 20x speed-up on average. However, there was another possible optimization, which was to change the data structure that was used to contain the data. With this last change we achieved a 40x speed-up on average.
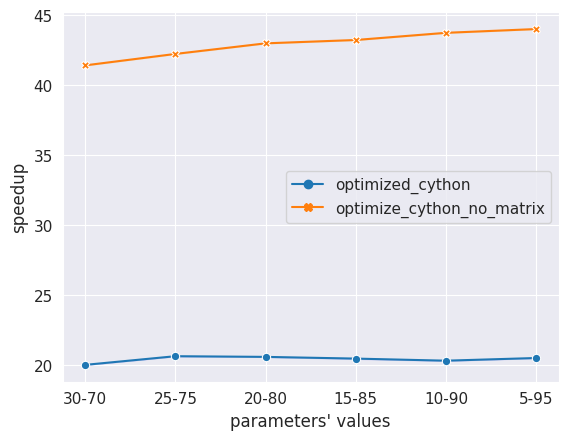
Cython UAV Path Planer optimization
In these two workloads we could optimize the code without requiring any kind of change in the infrastructure, so by just updating the code to the newest versions the platform performance is increased.
Speeding up performance with HPC
The High Performance Computing (HPC) is generally used to define clusters or even supercomputers, however this term is not only limited to making use of several machines. There are technologies like FPGA, NVMe and GPUs that can be used as specialized units in the computer to speed-up the computation. Specifically, GPUs have gained much attention in Machine Learning because they are a piece of hardware that is great to do many simple mathematical computations in parallel. In particular, matrix operations are great for Deep Learning models in both training and inference.
In the case of the multi-modal indexing application [4], there is a phase in which the well known VGG16 Deep Learning model is used to extract new variables (or features, as they are called in the Machine Learning field) that describe a given image. Performing inference with a GPU is usually faster than using the CPU (notice that there are some exceptions in parallel set-ups!), therefore we reimplemented that part of the code using CUDA [6], the library to perform operations on Nvidia GPUs. With that we achieved a 6x speed-up on average. However, this can also be parallelized, as performing inference on one image does not require the result of the others. Implementing multi-GPU support we were able to obtain a 12x speed-up on average with 2 GPUs and a 21x speed-up on average with 4GPUs. The improvement is almost linear with respect to the number of GPUs because of the independence of the tasks.
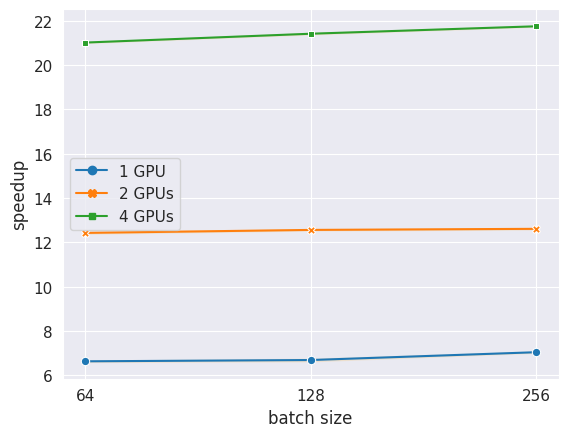
Multi-modal Hash training GPU optimization
Next steps
We have achieved very promising results with code optimization and the usage of HPC elements. On the next steps we will focus on applying distributed systems to the workloads to be able to use more resources in parallel, as we explained in a previous post [7]. Specifically, we are in the process of using GekkoFS [8], an distributed file system developed by Barcelona Supercomputing Center [9] and the Johannes Gutenberg-Universität Mainz [10] under the ADMIRE European Project [11]. This file system uses local storage, to provide a fast and scalable distributed file system that can hold many files like for example images to be processed. We hope that we can accelerate CALLISTO as much as possible!
References
[1] Amdahl’s law: https://en.wikipedia.org/wiki/Amdahl%27s_law
[2] Numba: https://numba.pydata.org/
[3] Cython: https://cython.org/
[4] M. Pegia, A. Moumtzidou, I. Gialampoukidis, B. Þ. Jónsson, S. Vrochidis and I. Kompatsiaris, “BiasHash: A Bayesian Hashing Framework for Image Retrieval,” 2022 IEEE 14th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP), 2022, pp. 1-5, doi: https://doi.org/10.1109/IVMSP54334.2022.9816233
[5] Apostolidis, S. D., Kapoutsis, P. C., Kapoutsis, A. C., & Kosmatopoulos, E. B. (2022). Cooperative multi-UAV coverage mission planning platform for remote sensing applications. Autonomous Robots, 1-28. https://doi.org/10.1007/s10514-021-10028-3
[6] Cuda: https://docs.nvidia.com/cuda-libraries/index.html
[7] Previous post: https://callisto-h2020.eu/optimizing-datacenters-for-high-performance-computation/
[8] GekkoFS: https://storage.bsc.es/projects/gekkofs/
[9] BSC: https://bsc.es
[10] JGU: https://www.uni-mainz.de/
[11] ADMIRE: https://www.admire-eurohpc.eu
Project Details
- DateDecember 1, 2022
- WriterAlberto Gutierrez-Torre and Ferran Agulló López, BSC
- 2
